8点台のAssignmentは1回だけだけど毎回10点満点くれるわけではないという感じでした
コード提出系はしつこいくらいに説明文を書かないとダメそうです
毎回どこかでin-text citationを使うことにするとSources and Evidenceのスコアも上がります
Final Exam前に習ったことをまとめておきます
Contents
1-1. データベースおよびDBMSの主な特徴
Eコマースプラットフォームを例にとると:
① データ完全性(Data Integrity)とデータ一貫性(Data Consistency)
DBMSは、複数の認可されたユーザーやアプリケーションが同時にデータを安全に共有できる仕組みを提供する。これにより、価格、在庫数、取引履歴といった情報の信頼性が保たれる。例えば、価格テーブルで商品価格を更新した場合、その変更は関連するすべてのテーブルやレポートに一貫して反映される必要がある。
② データセキュリティ(Data Security)
認証、認可、暗号化といったDBMSのセキュリティ機能により、顧客情報や取引データなどの機密情報が保護される。機密データへアクセスできるのは、権限を付与された担当者のみに制限される。
③ データ独立性(Data Independence)
データベースの構造と、それを利用するアプリケーションを分離する考え方をデータ独立性という。Eコマースでは商品カタログが頻繁に変更されるため、アプリケーションを大きく修正することなくデータ構造を変更できる点が重要である。
④ 効率的なデータ処理(Efficient Data Processing)
DBMSの主目的は、データを便利かつ効率的に保存・検索することである。高速な商品検索、リアルタイム在庫更新、スムーズな決済処理を実現するために不可欠である。階層型モデル、ネットワークモデル、特にリレーショナルモデルなどの情報モデルを活用することで、商品・顧客・注文・支払いといったエンティティを論理的かつ拡張性のある形で管理できる。
1-2. データベース設計に関わる主要な職種
データベースシステムの設計・運用には、複数の専門的な役割が存在する。
- データベース管理者(DBA):スキーマ定義、ストレージ構造、アクセス制御、日常的な保守作業を担当し、システムの信頼性を維持する。
- データベースアーキテクト:全体的なデータ構造を設計し、ビジネス目標や将来の拡張性を支える設計を行う。
- データモデラー:顧客の購買行動などの現実世界の要件を、概念モデルや論理モデルとして表現する。
- 開発者(Developers):DBMSと連携するアプリケーション層を構築し、クエリ、ストアドプロシージャ、APIなどを実装する。
- データアナリスト:蓄積されたデータを分析し、売上傾向、顧客行動、商品パフォーマンスなどの洞察を導き出す。
1-3. データベースモデルにおけるリレーションの発展
初期のデータベースモデルには、階層型モデルやネットワークモデルが存在した。
- 階層型モデルは1対多の関係しか表現できず、現実世界の複雑な関係を表現しにくく、冗長なデータ保存が必要になる場合があった。
- ネットワークモデルは多対多の関係を表現できるよう改善されたが、手続き的なナビゲーションが必要で、設計や運用が複雑だった。
これに対し、E. F. コッド博士によって提唱されたリレーショナルモデルは、データを行(タプル)と列(属性)からなる二次元の表(リレーション)として表現することで、データモデリングを大きく進化させた。エンティティ間の関係は物理的なポインタではなく、主キーと外部キーといった共通の値によって定義される。
ER図からリレーショナルテーブルへ変換する際には、関係集合に含まれる各エンティティの主キーを外部キーとして取り込み、参照整合性を維持する。この方法により、1対1、1対多、多対多の関係を一貫性を保ったまま表現できる。
一方で、RDBMSの導入には課題も存在する。ハードウェアやソフトウェアのコスト、既存のファイルベースシステムからのデータ移行の難しさ、性能面での制約、DBAなど専門人材の確保による運用コスト増加などが挙げられる。
ER(Entity-Relationship)図は、Eコマースデータベースにおける主要なエンティティ、その属性、そしてエンティティ間の関係を視覚的に表現するための設計手法である。
2. 概念設計(Conceptual Design)と物理設計(Physical Design)の違い
概念設計と物理設計の最大の違いは、抽象度の高さと役割にある。概念設計は「何を作るか(What)」を考える段階であり、物理設計は「どのように作るか(How)」を具体化する段階である。
概念設計では、特定の技術やDBMSに依存せず、業務上重要なエンティティとその関係を明確にする。データをどのように保存するかといった技術的詳細には踏み込まず、非技術者を含むステークホルダーとも共通理解を持つための設計図として機能する。
一方、物理設計では、概念設計・論理設計で定義された構造をもとに、実際のデータベース上のテーブル、主キー、外部キー、インデックス、ストレージ構成などを決定する。この段階では、使用するDBMSの性能特性、容量制約、運用面の要件などを考慮する必要がある。
また、技術依存性の観点でも両者は大きく異なる。概念設計はDBMS非依存で柔軟性が高いのに対し、物理設計は特定の技術に強く依存する。
このように、概念設計がシステム全体の枠組みを示す「設計図(Blueprint)」であるのに対し、物理設計はそれを実際のシステムとして構築するための「施工計画」に相当する。両者を明確に分離することで、技術的制約に縛られずに業務要件を整理できる点が、データモデリングの大きな利点である。
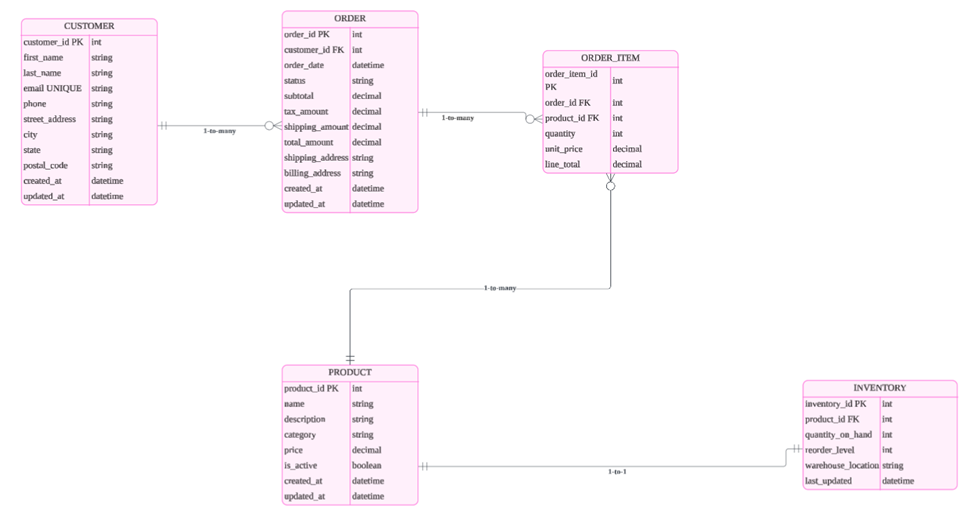
3. リレーショナルデータベース設計と正規化(Normalization)
正規化の定義と目的
正規化とは、大きく複雑なテーブルを、より小さく論理的に整理された複数のテーブルに分割することで、データ完全性を確保し、重複を減らし、データベース管理を容易にする手法である。正規化されたデータベースでは、構造が明確になるためクエリが書きやすくなり、処理効率の向上にもつながる。
正規化が不十分な場合、以下のような問題(アノマリー)が発生する。
- 挿入異常(Insertion anomaly):必要な情報が揃わないとデータを追加できない
- 更新異常(Update anomaly):同じ情報を複数箇所で更新する必要があり、不整合が生じる
- 削除異常(Deletion anomaly):不要なデータを削除した際に、重要な情報まで失われる
このため、正規化は効率的で保守性が高く、エラーの少ないデータベースを構築するうえで不可欠である。
Booksリレーションの正規化プロセス
未正規化の Books リレーションは以下の属性を持つ。
Books(Book_ID, Title, Author, Genre, Publisher, Publication_Year, ISBN, Price)
この関係では、以下の関数従属性が成り立つ。
Book_ID → Title, Author, Genre, Publisher, Publication_Year, ISBN, Price
① 第1正規形(1NF)
1NFでは、すべての属性が**原子値(分割不可能)**であることが求められる。1冊の本に複数の著者が含まれている場合、Author 属性が原子性を満たさないため、著者ごとに行を分割する必要がある。
② 第2正規形(2NF)
主キーが単一属性(Book_ID)のため部分関数従属は存在しないが、著者・出版社・ジャンルといった情報は書籍そのものではなく別エンティティに依存する。そのため、冗長性を排除するために以下のようにテーブルを分割する。
- Book(書籍)
- Author(著者)
- Book_Authors(書籍と著者の対応関係)
- Publisher(出版社)
- Genre(ジャンル)
これにより、多対多関係や重複データが適切に管理される。
③ 第3正規形(3NF)
3NFでは、**非キー属性が他の非キー属性に依存しない(推移的従属がない)**ことが条件となる。2NFの段階で著者や出版社などを分離しているため、この設計は3NFを満たしている。仮に出版社の住所などの情報を追加する場合でも、Publisher テーブルに属性を追加すれば Book テーブルに影響は及ばない。
④ ボイス・コッド正規形(BCNF)
BCNFは3NFよりも厳格な正規形で、すべての決定項が候補キーであることを要求する。例えば、出版社の連絡担当者が出版社名を一意に決定してしまう場合、決定項がスーパーキーでないためBCNFに違反する。
| Publisher_Name | Genre | Contact_Person |
| Alpha Science International | Computer Science | Alice Tanaka |
| Alpha Science International | Education | Alice Tanaka |
| TechPress | Computer Science | Bob Yamada |
このような場合、テーブルを「出版社と担当者」「出版社とジャンル」に分割することで、BCNF違反を解消できる。
| Publisher_Name | Contact_Person |
| Alpha Science International | Alice Tanaka |
| TechPress | Bob Yamada |
| Publisher_Name | Genre |
| Alpha Science International | Computer Science |
| Alpha Science International | Education |
| TechPress | Computer Science |
高次正規形の利点と欠点
3NFやBCNFといった高次の正規形を採用することで、以下の利点が得られる。
- データ重複の大幅な削減による整合性の向上
- 更新・挿入・削除時の不整合やアノマリーの防止
- 現実世界のエンティティ構造に近い、理解しやすいスキーマ
一方で、テーブル分割が進むことで以下のような欠点も生じる。
- JOIN が増え、クエリ性能が低下する可能性
- スキーマ構造が複雑になり、理解や実装の難易度が上がる
そのため、銀行システムや政府系システムのようにデータ完全性が最優先される分野では高次正規化が適している。一方、分析基盤やデータウェアハウスのように参照性能が重視されるシステムでは、あえて正規化レベルを下げる選択も現実的である。
4/5. SQL(Structured Query Language)の基礎と実践
SQLの役割
SQL(Structured Query Language)は、リレーショナルデータベースを操作・管理するための標準言語である。主に以下の目的で使用される。
- データベース構造の定義(DDL: Data Definition Language)
- データの追加・更新・削除(DML: Data Manipulation Language)
- データの検索・抽出(DQL: Data Query Language)
- 参照整合性の維持や制約の定義
SQL操作
- CREATE TABLE: テーブル作成
- INSERT:データを追加
- SELECT:JOIN を用いて Loans と Books を結合し、特定の会員が借りている書籍情報を取得する。これは複数テーブルに分かれたデータを統合して扱うSQLの代表的な例である。
- UPDATE:値の更新
- DELETE:特定の行を削除
外部キー制約と参照整合性
外部キー制約が有効な場合、データベースはテーブル間の参照整合性を自動的に保護する。例えば、Loans テーブルが MemberID を参照しているため、未返却の貸出記録が存在する会員を削除しようとすると、削除操作は拒否される。
これにより、参照先の存在しないデータ(孤児レコード)が発生するのを防ぎ、データの一貫性が維持される。
6. 集計・JOIN・高度なSQL構文の理解
複数科目を履修している学生の取得(GROUP BY / HAVING)
Students・Enrollments・Courses の3表構成において、「2科目以上を履修している学生」を取得するには、JOIN と集計関数を組み合わせたSQLを使用する。
|
1 2 3 4 |
SELECT s.student_name FROM Students s JOIN Enrollments e ON s.student_id = e.student_id GROUP BY s.student_id, s.student_name HAVING COUNT(e.course_id) >= 2; |
SQL JOINの種類と使い分け
SQLでは、複数のテーブルを結合するためにいくつかの JOIN が用意されており、目的に応じて使い分ける必要がある。
- INNER JOIN
両方のテーブルに一致するデータが存在する行のみを返す。履修している学生のみを取得したい場合など、関連データが必須のケースに適している。 - LEFT JOIN
左側のテーブルの全行を返し、右側に一致するデータがない場合は NULL を返す。全学生を対象にしつつ、履修状況を確認したい場合に有効である。 - RIGHT JOIN
RIGHT JOIN は LEFT JOIN の左右を入れ替えたものと同等の結果を得られる。SQLite では未対応のため、LEFT JOIN に書き換えて使用するのが一般的である。 - FULL JOIN
どちらか一方に一致する行があればすべて返す。未対応のDBMS(MySQLなど)では、LEFT JOIN と RIGHT JOIN を UNION で組み合わせることで同様の結果を得られる。主にデータ監査や不整合検出で利用される。
ビュー(View)の課題と制限
ビューは、複雑なクエリを抽象化し、セキュリティや再利用性を高める手段として有効であるが、いくつかの制約も存在する。
主な課題
- 更新不可または制限付きでしか更新できないビューが存在する
- 元テーブルの外部キーや NOT NULL 制約の影響を受けるため、INSERT や UPDATE 時に予期しないエラーが発生することがある
- クエリの実体が隠れることで、デバッグが難しくなる
対策
- WITH CHECK OPTION を使用し、ビュー定義条件を満たさないデータ操作を防ぐ
- NOT NULL 制約のある列をビューに含め、整合性エラーを回避する
- ビューの定義を簡潔に保ち、十分なドキュメントを整備する
このように、ビューは利便性と制約の両面を理解したうえで適切に設計・運用することが重要である。
7. データベースのトランザクションと接続技術
トランザクションは ACID特性(Atomicity, Consistency, Isolation, Durability) によって定義され、同時アクセスが発生するオンラインシステムにおいてもデータ整合性を維持する役割を果たす。
- Static SQL:定型処理
- Dynamic SQL:柔軟な検索条件を扱える
- Embedded SQL 業務ロジックと密接に連携
アプリケーションとDBMSを接続する技術
- JDBC:JDBCはJavaアプリケーションにおける標準的な接続方式であり、トランザクション制御や例外処理を通じて安全なデータ操作を可能にする
- ODBC :言語非依存であり、BIツールや外部分析基盤との連携に適している
8. データベース開発とライフサイクル管理
ウォーターフォールモデルは、要件分析 → システム設計 → 実装 → テスト → 導入 → 保守 という明確な段階で構成される。要件分析では、ユーザーが必要とするデータや業務ルールを明確化し、どのような情報をデータベースで管理すべきかを定義する。次の設計段階では、ER図や正規化を用いて概念設計・論理設計を行い、実装段階で実際のテーブルや制約を作成する。
このモデルの利点は、各工程の成果物が明確であり、文書化を通じて関係者間の合意形成がしやすい点にある。そのため、要件が安定している業務システムや、データ整合性が重視されるデータベース開発に適している。一方で、後工程での変更が困難という欠点もあり、要件変更が頻発するプロジェクトでは柔軟性に欠ける。
データベースライフサイクルの観点では、設計・実装後も運用、性能チューニング、バックアップ、障害対応といった継続的な管理が必要である。